Шифры слов разные. Коды и шифры
1. Простейшая система этого шифра заключается в том, что азбука разбивается на группы с равным числом букв и каждая из них обозначается двумя цифрами. Первая цифра обозначает группу, а вторая - порядковый номер буквы в этой группе.
АБВГ ДЕЖЗ ИКЛМ НОПР СТУФ ХЦЧШ ЩЫЮЯ
1 2 3 4 5 6 7
Зашифрованные слова, например «Уголовный розыск», будут выглядеть следующим образом:
53 14 42 33 42 13 41 72 31 44 42 24 72 51 32
Алфавит может браться и не в обычном порядке, а с любой перестановкой букв.
2. Шифр может быть усложнен по следующей схеме:
Буквы составляются из двух цифр. Первая - ее место в группе, а вторая обозначает номер группы. Например, слово «опасность» в зашифрованном виде будет выглядеть так:
33 37 14 32 34 33 32 35 58
Для усложнения прочтения слово можно записать в одну строку:
333714323433323558
3. Сюда же можно отнести и цифровое письмо, где буквы разделяются на пять групп, каждая из которых снабжается двумя номерами.
|
№ |
Каждая буква изображается дробью таким образом, что числителем ее будет номер группы, а знаменателем - номер места в группе. Так как при этой схеме не употребляются цифры свыше шести, то цифры с семи до девяти можно использовать как пустые знаки.
Этим шифром слово «день» может быть записано следующим образом:
71 81 30 57
95 76 19 38
4. Множительный шифр. Для работы с ним нужно запомнить кодовое число и заранее договориться, все ли буквы алфавита будут использоваться, не будут ли выкинуты какие-нибудь.
Предположим, что кодовым числом будет 257, а из алфавита исключаются буквы: й, ь, ъ, ы, т.е. он выглядит следующим образом:
АБВГДЕЁЖЗИКЛМНОПРСТУФЧЦЧШЩЭЮЯ
Требуется зашифровать выражение:
«Встреча завтра».
Текст пишется для удобства шифрования вразрядку:
В С Т Р Е Ч А З А В Т Р А
2 5 7 2 5 7 2 5 7 2 5 7 2
Под каждой буквой пишется по цифре до тех пор, пока не кончится фраза. Затем вместо каждой буквы текста пишется та буква алфавита, которая по счету оказывается первой вслед за таким количеством букв, какое показывает цифра, стоящая внизу, причем счет производится вправо. Так, под первой буквой «В» стоит цифра «2», поэтому вместо буквы «В» в шифровальном письме ставится третья буква алфавита «Д». Под второй буквой текста «С» стоит цифр «5», поэтому вместо нее ставится шестая после «С», т.е. буква «Ц».
В цифрованном виде письмо приобретет следующий вид:
ДЦШТКБВ НЖДЧЧВ
Для прочтения шифровки необходимо под каждую букву поставить ключевое, кодовое число. В нашем случае число 257. А в алфавите отсчитывать влево от данной буквы шифрованного письма столько букв, сколько показывает стоящая перед нею цифра.
Значит, вместо буквы «Д» вторая налево будет буква «В», а вместо «Ц» пятая, значит буква «С».
Д Ц Щ Т К Б В Н Ж Д Ч Ч В
2 5 7 2 5 7 2 5 7 2 5 7 2
В С Т Р Е Ч А З А В Т Р А
По материалам Л.А.Мильяненков
По ту сторону закона
энциклопедия преступного мира
Воспользоваться старой и малоизвестной системой записи. Даже римские цифры не всегда бывает легко прочитать, особенно с первого взгляда и без справочника. Мало кто сможет «с лёта» определить, что в длинной строчке MMMCDLXXXIX скрывается число 3489.
С римской системой счисления знакомы многие, поэтому ее нельзя назвать надежной для шифрования. Гораздо лучше прибегнуть, например, к греческой системе, где цифры также обозначаются буквами, но букв используется намного больше. В надписи ОМГ, которую легко принять за распространенное в интернете выражение эмоций, может быть спрятано записанное по-гречески число 443. Буква «О микрон» соответствует числу 400, буквой «Мю» обозначается 40, ну а «Гамма» заменяет тройку.
Недостаток подобных буквенных систем в том, что они зачастую требуют экзотических букв и знаков. Это не составляет особого труда, если ваш шифр записан ручкой на бумаге, но превращается в проблему, если вы хотите отправить его, скажем, по электронной почте. Компьютерные шрифты включают в себя греческие символы, но их бывает сложно набирать. А если вы выбрали что-то еще более необычное, вроде старой кириллической записи или египетских числовых , то компьютер просто не сможет их передать.
Для таких случаев можно рекомендовать простой способ, которым в России в старые времена пользовались все те же бродячие торговцы - коробейники и офени. Для успешной торговли им было жизненно необходимо согласовывать между собой цены, но так, чтобы об этом не узнал никто посторонний. Поэтому коробейники и разработали множество хитроумных способов шифровки.
С цифрами они обходились следующим образом. Вначале нужно взять слово в котором есть десять различных букв, например «правосудие». Затем буквы нумеруются от единицы до нуля. «П» становится знаком для единицы, «в» - для четверки, и так далее. После этого любое число можно записывать буквами вместо цифр по обычной десятичной системе. Например, год 2011 записывается по системе офеней как «реепп». Попробуйте сами , спрятано в строчке «а,пвпоирс».
«Правосудие» - не единственное слово русского языка, подходящее для этого метода. «Трудолюбие» годится ничуть не хуже: в нем также десять неповторяющихся букв. Вы вполне можете и самостоятельно поискать другие возможные основы.
Не зря историю Египта считают одной из самых таинственных, а культуру одной из высокоразвитых. Древние египтяне, не в пример многим народам, не только умели возводить пирамиды и мумифицировать тела, но владели грамотой, вели счет, вычисляли небесные светила, фиксируя их координаты.
Десятичная система Египта
Современная десятичная появилась чуть более 2000 лет назад, однако египтяне владели ее аналогом еще во времена фараонов. Вместо громоздких индивидуальных буквенно-знаковых обозначений числа они использовали унифицированные знаки – графические изображения, цифры. Цифры они делили на единицы, десятки, сотни и т.д., обозначая каждую категорию специальным иероглифом.
Как такового правила цифр не было, то есть их могли в любом порядке, например, справа налево, слева направо. Иногда их даже составляли в вертикальную строку, при этом направление чтения цифрового ряда задавалось видом первой цифры – вытянутая (для вертикального чтения) или сплюснутая (для горизонтального).
Найденные при раскопках древние папирусы с цифрами свидетельствуют, что египтяне уже в то время рассматривали различные арифметические , проводили исчисления и при помощи цифр фиксировали результат, применяли цифровые обозначения в области геометрии. Это значит, что цифровая запись была распространенной и общепринятой.
Цифры нередко наделялись магическим и знаковым значением, о чем свидетельствует их изображение не только на папирусах, но и на саркофагах, стенах усыпальниц.
Вид цифры
Цифровые иероглифы были геометричны и состояли только из прямых. Иероглифы выглядели достаточно просто, например цифра «1» у египтян обозначалась одной вертикальной полоской, «2» - двумя, «3» - тремя. А вот некоторые цифры, написанные , не поддаются современной логике, примером служит цифра «4», которая изображалась как одна горизонтальная полоска, а цифра «8» в виде двух горизонтальных полосок. Самыми сложными в написании считались цифры девять и шесть, они состояли из характерных черт под разным наклоном.
Долгие годы египтологи не могли расшифровать эти иероглифы, полагая, что перед ними буквы или слова.
Одними из последних были расшифрованы и переведены иероглифы, обозначающих массу, совокупность. Сложность была объективной, ведь некоторые цифры изображались символично, к примеру, на папирусах человек, изображенный с поднятыми , обозначал миллион. Иероглиф с изображением жабы означал тысячу, а личинки - . Однако вся система написания цифр была систематизированной, очевидно – утверждают египтологи – что иероглифы упрощались. Вероятно, их написанию и обозначению обучали даже простой народ, потому как обнаруженные многочисленные торговые грамоты мелких лавочников были составлены грамотно.
Поскольку шифров в мире насчитывается огромное количество, то рассмотреть все шифры невозможно не только в рамках данной статьи, но и целого сайта. Поэтому рассмотрим наиболее примитивные системы шифрации, их применение, а так же алгоритмы расшифровки. Целью своей статьи я ставлю максимально доступно объяснить широкому кругу пользователей принципов шифровки \ дешифровки, а так же научить примитивным шифрам.
Еще в школе я пользовался примитивным шифром, о котором мне поведали более старшие товарищи. Рассмотрим примитивный шифр «Шифр с заменой букв цифрами и обратно».
Нарисуем таблицу, которая изображена на рисунке 1. Цифры располагаем по порядку, начиная с единицы, заканчивая нулем по горизонтали. Ниже под цифрами подставляем произвольные буквы или символы.
Рис. 1 Ключ к шифру с заменой букв и обратно.
Теперь обратимся к таблице 2, где алфавиту присвоена нумерация.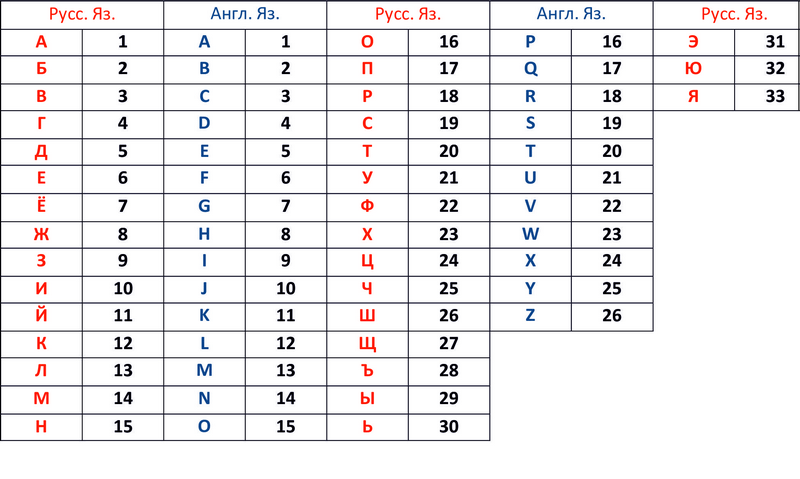
Рис. 2 Таблица соответствия букв и цифр алфавитов.
Теперь зашифруем словоК О С Т Е Р :
1) 1. Переведем буквы в цифры:К = 12, О = 16, С =19, Т = 20, Ё = 7, Р = 18
2) 2. Переведем цифры в символы согласно таблицы 1.
КП КТ КД ПЩ Ь КЛ
3) 3. Готово.
Этот пример показывает примитивный шифр. Рассмотрим похожие по сложности шрифты.
1. 1. Самым простым шифром является ШИФР С ЗАМЕНОЙ БУКВ ЦИФРАМИ. Каждой букве соответствует число по алфавитному порядку. А-1, B-2, C-3 и т.д.
Например слово «TOWN » можно записать как «20 15 23 14», но особой секретности и сложности в дешифровке это не вызовет.
2. Также можно зашифровывать сообщения с помощью ЦИФРОВОЙ ТАБЛИЦЫ. Её параметры могут быть какими угодно, главное, чтобы получатель и отправитель были в курсе. Пример цифровой таблицы.
Рис. 3 Цифровая таблица. Первая цифра в шифре – столбец, вторая – строка или наоборот. Так слово «MIND» можно зашифровать как «33 24 34 14».
3. 3. КНИЖНЫЙ ШИФР
В таком шифре ключом является некая книга, имеющаяся и у отправителя и у получателя. В шифре обозначается страница книги и строка, первое слово которой и является разгадкой. Дешифровка невозможна, если книги у отправителя и корреспондента разных годов издания и выпуска. Книги обязательно должны быть идентичными.
4. 4. ШИФР ЦЕЗАРЯ
(шифр сдвига, сдвиг Цезаря)
Известный шифр. Сутью данного шифра является замена одной буквы другой, находящейся на некоторое постоянное число позиций левее или правее от неё в алфавите. Гай Юлий Цезарь использовал этот способ шифрования при переписке со своими генералами для защиты военных сообщений. Этот шифр довольно легко взламывается, поэтому используется редко. Сдвиг на 4. A = E, B= F, C=G, D=H и т.д.
Пример шифра Цезаря: зашифруем слово « DEDUCTION » .
Получаем: GHGXFWLRQ . (сдвиг на 3)
Еще пример:
Шифрование с использованием ключа К=3 . Буква «С» «сдвигается» на три буквы вперёд и становится буквой «Ф». Твёрдый знак, перемещённый на три буквы вперёд, становится буквой «Э», и так далее:
Исходный алфавит:А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
Шифрованный:Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В
Оригинальный текст:
Съешь же ещё этих мягких французских булок, да выпей чаю.
Шифрованный текст получается путём замены каждой буквы оригинального текста соответствующей буквой шифрованного алфавита:
Фэзыя йз зьи ахлш пвёнлш чугрщцкфнлш дцосн, жг еютзм ъгб.
5. ШИФР С КОДОВЫМ СЛОВОМ
Еще один простой способ как в шифровании, так и в расшифровке. Используется кодовое слово (любое слово без повторяющихся букв). Данное слово вставляется впереди алфавита и остальные буквы по порядку дописываются, исключая те, которые уже есть в кодовом слове. Пример: кодовое слово – NOTEPAD.
Исходный:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Замена:N O T E P A D B C F G H I J K L M Q R S U V W X Y Z
6. 6. ШИФР АТБАШ
Один из наиболее простых способов шифрования. Первая буква алфавита заменяется на последнюю, вторая – на предпоследнюю и т.д.
Пример: « SCIENCE » = HXRVMXV
7. 7. ШИФР ФРЕНСИСА БЭКОНА
Один из наиболее простых методов шифрования. Для шифрования используется алфавит шифра Бэкона: каждая буква слова заменяется группой из пяти букв «А» или «B» (двоичный код).
a AAAAA g AABBA m ABABB s BAAAB y BABBA
b AAAAB h AABBB n ABBAA t BAABA z BABBB
c AAABA i ABAAA o ABBAB u BAABB
d AAABB j BBBAA p ABBBA v BBBAB
e AABAA k ABAAB q ABBBB w BABAA
f AABAB l ABABA r BAAAA x BABAB
Сложность дешифрования заключается в определении шифра. Как только он определен, сообщение легко раскладывается по алфавиту.
Существует несколько способов кодирования.
Также можно зашифровать предложение с помощью двоичного кода. Определяются параметры (например, «А» - от A до L, «В» - от L до Z). Таким образом, BAABAAAAABAAAABABABB означает TheScience of Deduction ! Этот способ более сложен и утомителен, но намного надежнее алфавитного варианта.
8. 8. ШИФР БЛЕЗА ВИЖЕНЕРА.
Этот шифр использовался конфедератами во время Гражданской войны. Шифр состоит из 26 шифров Цезаря с различными значениями сдвига (26 букв лат.алфавита). Для зашифровывания может использоваться tabula recta (квадрат Виженера). Изначально выбирается слово-ключ и исходный текст. Слово ключ записывается циклически, пока не заполнит всю длину исходного текста. Далее по таблице буквы ключа и исходного текста пересекаются в таблице и образуют зашифрованный текст.

Рис. 4 Шифр Блеза Виженера
9. 9. ШИФР ЛЕСТЕРА ХИЛЛА
Основан на линейной алгебре. Был изобретен в 1929 году.
В таком шифре каждой букве соответствует число (A = 0, B =1 и т.д.). Блок из n-букв рассматривается как n-мерный вектор и умножается на (n х n) матрицу по mod 26. Матрица и является ключом шифра. Для возможности расшифровки она должна быть обратима в Z26n.
Для того, чтобы расшифровать сообщение, необходимо обратить зашифрованный текст обратно в вектор и умножить на обратную матрицу ключа. Для подробной информации – Википедия в помощь.
10. 10. ШИФР ТРИТЕМИУСА
Усовершенствованный шифр Цезаря. При расшифровке легче всего пользоваться формулой:
L= (m+k) modN , L-номер зашифрованной буквы в алфавите, m-порядковый номер буквы шифруемого текста в алфавите, k-число сдвига, N-количество букв в алфавите.
Является частным случаем аффинного шифра.
11. 11. МАСОНСКИЙ ШИФР
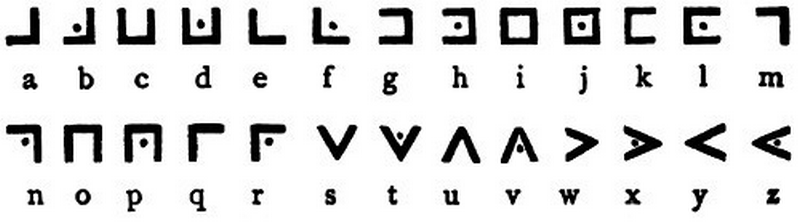

12. 12. ШИФР ГРОНСФЕЛЬДА
По своему содержанию этот шифр включает в себя шифр Цезаря и шифр Виженера, однако в шифре Гронсфельда используется числовой ключ. Зашифруем слово “THALAMUS”, используя в качестве ключа число 4123. Вписываем цифры числового ключа по порядку под каждой буквой слова. Цифра под буквой будет указывать на количество позиций, на которые нужно сдвинуть буквы. К примеру вместо Т получится Х и т.д.
T H A L A M U S
4 1 2 3 4 1 2 3
T U V W X Y Z
0 1 2 3 4
В итоге: THALAMUS = XICOENWV
13. 13. ПОРОСЯЧЬЯ ЛАТЫНЬ
Чаще используется как детская забава, особой трудности в дешифровке не вызывает. Обязательно употребление английского языка, латынь здесь ни при чем.
В словах, начинающихся с согласных букв, эти согласные перемещаются назад и добавляется “суффикс” ay. Пример: question = estionquay. Если же слово начинается с гласной, то к концу просто добавляется ay, way, yay или hay (пример: a dog = aay ogday).
В русском языке такой метод тоже используется. Называют его по-разному: “синий язык”, “солёный язык”, “белый язык”, “фиолетовый язык”. Таким образом, в Синем языке после слога, содержащего гласную, добавляется слог с этой же гласной, но с добавлением согласной “с” (т.к. язык синий). Пример:Информация поступает в ядра таламуса = Инсифорсомасацисияся поссотусупасаетсе в ядсяраса тасаласамусусаса.
Довольно увлекательный вариант.
14. 14. КВАДРАТ ПОЛИБИЯ
Подобие цифровой таблицы. Существует несколько методов использования квадрата Полибия. Пример квадрата Полибия: составляем таблицу 5х5 (6х6 в зависимости от количества букв в алфавите).

1 МЕТОД. Вместо каждой буквы в слове используется соответствующая ей буква снизу (A = F, B = G и т.д.). Пример: CIPHER - HOUNIW.
2 МЕТОД. Указываются соответствующие каждой букве цифры из таблицы. Первой пишется цифра по горизонтали, второй - по вертикали. (A = 11, B = 21…). Пример: CIPHER = 31 42 53 32 51 24
3 МЕТОД. Основываясь на предыдущий метод, запишем полученный код слитно. 314253325124. Делаем сдвиг влево на одну позицию. 142533251243. Снова разделяем код попарно.14 25 33 25 12 43. В итоге получаем шифр. Пары цифр соответствуют букве в таблице: QWNWFO.
Шифров великое множество, и вы так же можете придумать свой собственный шифр, однако изобрести стойкий шифр очень сложно, поскольку наука дешифровки с появлением компьютеров шагнула далеко вперед и любой любительский шифр будет взломан специалистами за очень короткое время.
Методы вскрытия одноалфавитных систем (расшифровка)
При своей простоте в реализации одноалфавитные системы шифрования легко уязвимы.
Определим количество различных систем в аффинной системе. Каждый ключ полностью определен парой целых чисел a и b, задающих отображение ax+b. Для а существует j(n) возможных значений, где j(n) - функция Эйлера, возвращающая количество взаимно простых чисел с n, и n значений для b, которые могут быть использованы независимо от a, за исключением тождественного отображения (a=1 b=0), которое мы рассматривать не будем.
Таким образом получается j(n)*n-1 возможных значений, что не так уж и много: при n=33 в качестве a могут быть 20 значений(1, 2, 4, 5, 7, 8, 10, 13, 14, 16, 17, 19, 20, 23, 25, 26, 28, 29, 31, 32), тогда общее число ключей равно 20*33-1=659. Перебор такого количества ключей не составит труда при использовании компьютера.
Но существуют методы упрощающие этот поиск и которые могут быть использованы при анализе более сложных шифров.
Частотный анализ
Одним из таких методов является частотный анализ. Распределение букв в криптотексте сравнивается с распределением букв в алфавите исходного сообщения. Буквы с наибольшей частотой в криптотексте заменяются на букву с наибольшей частотой из алфавита. Вероятность успешного вскрытия повышается с увеличением длины криптотекста.
Существуют множество различных таблиц о распределении букв в том или ином языке, но ни одна из них не содержит окончательной информации - даже порядок букв может отличаться в различных таблицах. Распределение букв очень сильно зависит от типа теста: проза, разговорный язык, технический язык и т.п. В методических указаниях к лабораторной работе приведены частотные характеристики для различных языков, из которых ясно, что буквы буквы I, N, S, E, A (И, Н, С, Е, А) появляются в высокочастотном классе каждого языка.
Простейшая защита против атак, основанных на подсчете частот, обеспечивается в системе омофонов (HOMOPHONES) - однозвучных подстановочных шифров, в которых один символ открытого текста отображается на несколько символов шифротекста, их число пропорционально частоте появления буквы. Шифруя букву исходного сообщения, мы выбираем случайно одну из ее замен. Следовательно простой подсчет частот ничего не дает криптоаналитику. Однако доступна информация о распределении пар и троек букв в различных естественных языках.
Необходимость в шифровании переписки возникла еще в древнем мире, и появились шифры простой замены. Зашифрованные послания определяли судьбу множества битв и влияли на ход истории. Со временем люди изобретали все более совершенные способы шифрования.
Код и шифр - это, к слову, разные понятия. Первое означает замену каждого слова в сообщении кодовым словом. Второе же заключается в шифровании по определенному алгоритму каждого символа информации.
После того как кодированием информации занялась математика и была разработана теория криптографии, ученые обнаружили множество полезных свойств этой прикладной науки. Например, алгоритмы декодирования помогли разгадать мертвые языки, такие как древнеегипетский или латынь.
Стеганография
Стеганография старше кодирования и шифрования. Это искусство появилось очень давно. Оно буквально означает «скрытое письмо» или «тайнопись». Хоть стеганография не совсем соответствует определениям кода или шифра, но она предназначена для сокрытия информации от чужих глаз.
Стеганография является простейшим шифром. Типичными ее примерами являются проглоченные записки, покрытые ваксой, или сообщение на бритой голове, которое скрывается под выросшими волосами. Ярчайшим примером стеганографии является способ, описанный во множестве английских (и не только) детективных книг, когда сообщения передаются через газету, где малозаметным образом помечены буквы.
Главным минусом стеганографии является то, что внимательный посторонний человек может ее заметить. Поэтому, чтобы секретное послание не было легко читаемым, совместно со стеганографией используются методы шифрования и кодирования.
ROT1 и шифр Цезаря
Название этого шифра ROTate 1 letter forward, и он известен многим школьникам. Он представляет собой шифр простой замены. Его суть заключается в том, что каждая буква шифруется путем смещения по алфавиту на 1 букву вперед. А -> Б, Б -> В, ..., Я -> А. Например, зашифруем фразу «наша Настя громко плачет» и получим «общб Обтуа дспнлп рмбшеу».
Шифр ROT1 может быть обобщен на произвольное число смещений, тогда он называется ROTN, где N - это число, на которое следует смещать шифрование букв. В таком виде шифр известен с глубокой древности и носит название «шифр Цезаря».

Шифр Цезаря очень простой и быстрый, но он является шифром простой одинарной перестановки и поэтому легко взламывается. Имея подобный недостаток, он подходит только для детских шалостей.
Транспозиционные или перестановочные шифры
Данные виды шифра простой перестановки более серьезны и активно применялись не так давно. В Гражданскую войну в США и в Первую мировую его использовали для передачи сообщений. Его алгоритм заключается в перестановке букв местами - записать сообщение в обратном порядке или попарно переставить буквы. Например, зашифруем фразу «азбука Морзе - тоже шифр» -> «акубза езроМ - ежот рфиш».
С хорошим алгоритмом, который определял произвольные перестановки для каждого символа или их группы, шифр становился устойчивым к простому взлому. Но! Только в свое время. Так как шифр легко взламывается простым перебором или словарным соответствием, сегодня с его расшифровкой справится любой смартфон. Поэтому с появлением компьютеров этот шифр также перешел в разряд детских.
Азбука Морзе
Азбука является средством обмена информации и ее основная задача - сделать сообщения более простыми и понятными для передачи. Хотя это противоречит тому, для чего предназначено шифрование. Тем не менее она работает подобно простейшим шифрам. В системе Морзе каждая буква, цифра и знак препинания имеют свой код, составленный из группы тире и точек. При передаче сообщения с помощью телеграфа тире и точки означают длинные и короткие сигналы.

Телеграф и азбука был тем, кто первый запатентовал «свое» изобретение в 1840 году, хотя до него и в России, и в Англии были изобретены подобные аппараты. Но кого это теперь интересует... Телеграф и азбука Морзе оказали очень большое влияние на мир, позволив почти мгновенно передавать сообщения на континентальные расстояния.
Моноалфавитная замена
Описанные выше ROTN и азбука Морзе являются представителями шрифтов моноалфавитной замены. Приставка «моно» означает, что при шифровании каждая буква изначального сообщения заменяется другой буквой или кодом из единственного алфавита шифрования.
Дешифрование шифров простой замены не составляет труда, и в этом их главный недостаток. Разгадываются они простым перебором или Например, известно, что самые используемые буквы русского языка - это «о», «а», «и». Таким образом, можно предположить, что в зашифрованном тексте буквы, которые встречаются чаще всего, означают либо «о», либо «а», либо «и». Исходя из таких соображений, послание можно расшифровать даже без перебора компьютером.
Известно, что Мария I, королева Шотландии с 1561 по 1567 г., использовала очень сложный шифр моноалфавитной замены с несколькими комбинациями. И все же ее враги смогли расшифровать послания, и информации хватило, чтобы приговорить королеву к смерти.
Шифр Гронсфельда, или полиалфавитная замена
Простые шифры криптографией признаны бесполезными. Поэтому множество из них было доработано. Шифр Гронсфельда — это модификация шифра Цезаря. Данный способ является значительно более стойким к взлому и заключается в том, что каждый символ кодируемой информации шифруется при помощи одного из разных алфавитов, которые циклически повторяются. Можно сказать, что это многомерное применение простейшего шифра замены. Фактически шифр Гронсфельда очень похож на рассмотренный ниже.
Алгоритм шифрования ADFGX
Это самый известный шифр Первой мировой войны, используемый немцами. Свое имя шифр получил потому, что алгоритм шифрования приводил все шифрограммы к чередованию этих букв. Выбор самих же букв был определен их удобством при передаче по телеграфным линиям. Каждая буква в шифре представляется двумя. Рассмотрим более интересную версию квадрата ADFGX, которая включает цифры и называется ADFGVX.
| A | D | F | G | V | X | |
| A | J | Q | A | 5 | H | D |
| D | 2 | E | R | V | 9 | Z |
| F | 8 | Y | I | N | K | V |
| G | U | P | B | F | 6 | O |
| V | 4 | G | X | S | 3 | T |
| X | W | L | Q | 7 | C | 0 |
Алгоритм составления квадрата ADFGX следующий:
- Берем случайные n букв для обозначения столбцов и строк.
- Строим матрицу N x N.
- Вписываем в матрицу алфавит, цифры, знаки, случайным образом разбросанные по ячейкам.
Составим аналогичный квадрат для русского языка. Например, создадим квадрат АБВГД:
| А | Б | В | Г | Д | |
| А | Е/Е | Н | Ь/Ъ | А | И/Й |
| Б | Ч | В/Ф | Г/К | З | Д |
| В | Ш/Щ | Б | Л | Х | Я |
| Г | Р | М | О | Ю | П |
| Д | Ж | Т | Ц | Ы | У |
Данная матрица выглядит странно, так как ряд ячеек содержит по две буквы. Это допустимо, смысл послания при этом не теряется. Его легко можно восстановить. Зашифруем фразу «Компактный шифр» при помощи данной таблицы:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
| Фраза | К | О | М | П | А | К | Т | Н | Ы | Й | Ш | И | Ф | Р |
| Шифр | бв | гв | гб | гд | аг | бв | дб | аб | дг | ад | ва | ад | бб | га |
Таким образом, итоговое зашифрованное послание выглядит так: «бвгвгбгдагбвдбабдгвдваадббга». Разумеется, немцы проводили подобную строку еще через несколько шифров. И в итоге получалось очень устойчивое к взлому шифрованное послание.
Шифр Виженера
Данный шифр на порядок более устойчив к взлому, чем моноалфавитные, хотя представляет собой шифр простой замены текста. Однако благодаря устойчивому алгоритму долгое время считался невозможным для взлома. Первые его упоминания относятся к 16-му веку. Виженер (французский дипломат) ошибочно считается его изобретателем. Чтобы лучше разобраться, о чем идет речь, рассмотрим таблицу Виженера (квадрат Виженера, tabula recta) для русского языка.

Приступим к шифрованию фразы «Касперович смеется». Но, чтобы шифрование удалось, нужно ключевое слово — пусть им будет «пароль». Теперь начнем шифрование. Для этого запишем ключ столько раз, чтобы количество букв из него соответствовало количеству букв в шифруемой фразе, путем повтора ключа или обрезания:
Теперь по как по координатной плоскости, ищем ячейку, которая является пересечением пар букв, и получаем: К + П = Ъ, А + А = Б, С + Р = В и т. д.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | |
| Шифр: | Ъ | Б | В | Ю | С | Н | Ю | Г | Щ | Ж | Э | Й | Х | Ж | Г | А | Л |
Получаем, что "касперович смеется" = "ъбвюснюгщж эйхжгал".
Взломать шифр Виженера так сложно, потому что для работы частотного анализа необходимо знать длину ключевого слова. Поэтому взлом заключается в том, чтобы наугад бросать длину ключевого слова и пытаться взломать засекреченное послание.
Следует также упомянуть, что помимо абсолютно случайного ключа может быть использована совершенно разная таблица Виженера. В данном случае квадрат Виженера состоит из построчно записанного русского алфавита со смещением на единицу. Что отсылает нас к шифру ROT1. И точно так же, как и в шифре Цезаря, смещение может быть любым. Более того, порядок букв не должен быть алфавитным. В данном случае сама таблица может быть ключом, не зная которую невозможно будет прочесть сообщение, даже зная ключ.
Коды
Настоящие коды состоят из соответствий для каждого слова отдельного кода. Для работы с ними необходимы так называемые кодовые книги. Фактически это тот же словарь, только содержащий переводы слов в коды. Типичным и упрощенным примером кодов является таблица ASCII — международный шифр простых знаков.

Главным преимуществом кодов является то, что расшифровать их очень сложно. Частотный анализ почти не работает при их взломе. Слабость же кодов — это, собственно, сами книги. Во-первых, их подготовка — сложный и дорогостоящий процесс. Во-вторых, для врагов они превращаются в желанный объект и перехват даже части книги вынуждает менять все коды полностью.
В 20-м веке многие государства для передачи секретных данных использовали коды, меняя кодовую книгу по прошествии определенного периода. И они же активно охотились за книгами соседей и противников.
"Энигма"
Всем известно, что "Энигма" — это главная шифровальная машина нацистов во время II мировой войны. Строение "Энигмы" включает комбинацию электрических и механических схем. То, каким получится шифр, зависит от начальной конфигурации "Энигмы". В то же время "Энигма" автоматически меняет свою конфигурацию во время работы, шифруя одно сообщение несколькими способами на всем его протяжении.
В противовес самым простым шифрам "Энигма" давала триллионы возможных комбинаций, что делало взлом зашифрованной информации почти невозможным. В свою очередь, у нацистов на каждый день была заготовлена определенная комбинация, которую они использовали в конкретный день для передачи сообщений. Поэтому даже если "Энигма" попадала в руки противника, она никак не способствовала расшифровке сообщений без введения нужной конфигурации каждый день.

Взломать "Энигму" активно пытались в течение всей военной кампании Гитлера. В Англии в 1936 г. для этого построили один из первых вычислительных аппаратов (машина Тьюринга), ставший прообразом компьютеров в будущем. Его задачей было моделирование работы нескольких десятков "Энигм" одновременно и прогон через них перехваченных сообщений нацистов. Но даже машине Тьюринга лишь иногда удавалось взламывать сообщение.
Шифрование методом публичного ключа
Самый популярный из который используется повсеместно в технике и компьютерных системах. Его суть заключается, как правило, в наличии двух ключей, один из которых передается публично, а второй является секретным (приватным). Открытый ключ используется для шифровки сообщения, а секретный — для дешифровки.

В роли открытого ключа чаще всего выступает очень большое число, у которого существует только два делителя, не считая единицы и самого числа. Вместе эти два делителя образуют секретный ключ.
Рассмотрим простой пример. Пусть публичным ключом будет 905. Его делителями являются числа 1, 5, 181 и 905. Тогда секретным ключом будет, например, число 5*181. Вы скажете слишком просто? А что если в роли публичного числа будет число с 60 знаками? Математически сложно вычислить делители большого числа.
В качестве более живого примера представьте, что вы снимаете деньги в банкомате. При считывании карточки личные данные зашифровываются определенным открытым ключом, а на стороне банка происходит расшифровка информации секретным ключом. И этот открытый ключ можно менять для каждой операции. А способов быстро найти делители ключа при его перехвате — нет.
Стойкость шрифта
Криптографическая стойкость алгоритма шифрования — это способность противостоять взлому. Данный параметр является самым важным для любого шифрования. Очевидно, что шифр простой замены, расшифровку которого осилит любое электронное устройство, является одним из самых нестойких.
На сегодняшний день не существует единых стандартов, по которым можно было бы оценить стойкость шифра. Это трудоемкий и долгий процесс. Однако есть ряд комиссий, которые изготовили стандарты в этой области. Например, минимальные требования к алгоритму шифрования Advanced Encryption Standart или AES, разработанные в NIST США.
Для справки: самым стойким шифром к взлому признан шифр Вернама. При этом его плюсом является то, что по своему алгоритму он является простейшим шифром.
В шифрах замены (или шифрах подстановки), в отличие от , элементы текста не меняют свою последовательность, а изменяются сами, т.е. происходит замена исходных букв на другие буквы или символы (один или несколько) по неким правилам.
На этой страничке описаны шифры, в которых замена происходит на буквы или цифры. Когда же замена происходит на какие-то другие не буквенно-цифровые символы, на комбинации символов или рисунки, это называют прямым .
Моноалфавитные шифры
В шифрах с моноалфавитной заменой каждая буква заменяется на одну и только одну другую букву/символ или группу букв/символов. Если в алфавите 33 буквы, значит есть 33 правила замены: на что менять А, на что менять Б и т.д.
Такие шифры довольно легко расшифровать даже без знания ключа. Делается это при помощи частотного анализа зашифрованного текста - надо посчитать, сколько раз каждая буква встречается в тексте, и затем поделить на общее число букв. Получившуюся частоту надо сравнить с эталонной. Самая частая буква для русского языка - это буква О, за ней идёт Е и т.д. Правда, работает частотный анализ на больших литературных текстах. Если текст маленький или очень специфический по используемым словам, то частотность букв будет отличаться от эталонной, и времени на разгадывание придётся потратить больше. Ниже приведена таблица частотности букв (то есть относительной частоты встречаемых в тексте букв) русского языка, рассчитанная на базе НКРЯ .
Использование метода частотного анализа для расшифровки шифрованных сообщений красиво описано во многих литературных произведениях, например, у Артура Конана Дойля в романе « » или у Эдгара По в « ».
Составить кодовую таблицу для шифра моноалфавитной замены легко, но запомнить её довольно сложно и при утере восстановить практически невозможно, поэтому обычно придумывают какие-то правила составления таких кодовых страниц. Ниже приведены самые известные из таких правил.
Случайный код
Как я уже писал выше, в общем случае для шифра замены надо придумать, какую букву на какую надо заменять. Самое простое - взять и случайным образом перемешать буквы алфавита, а потом их выписать под строчкой алфавита. Получится кодовая таблица. Например, вот такая:
Число вариантов таких таблиц для 33 букв русского языка = 33! ≈ 8.683317618811886*10 36 . С точки зрения шифрования коротких сообщений - это самый идеальный вариант: чтобы расшифровать, надо знать кодовую таблицу. Перебрать такое число вариантов невозможно, а если шифровать короткий текст, то и частотный анализ не применишь.
Но для использования в квестах такую кодовую таблицу надо как-то по-красивее преподнести. Разгадывающий должен для начала эту таблицу либо просто найти, либо разгадать некую словесно-буквенную загадку. Например, отгадать или решить .
Ключевое слово
Один из вариантов составления кодовой таблицы - использование ключевого слова. Записываем алфавит, под ним вначале записываем ключевое слово, состоящее из неповторяющихся букв, а затем выписываем оставшиеся буквы. Например, для слова «манускрипт» получим вот такую таблицу:
Как видим, начало таблицы перемешалось, а вот конец остался неперемешенным. Это потому, что самая «старшая» буква в слове «манускрипт» - буква «У», вот после неё и остался неперемешенный «хвост». Буквы в хвосте останутся незакодированными. Можно оставить и так (так как большая часть букв всё же закодирована), а можно взять слово, которое содержит в себе буквы А и Я, тогда перемешаются все буквы, и «хвоста» не будет.
Само же ключевое слово можно предварительно тоже загадать, например при помощи или . Например, вот так:

Разгадав арифметический ребус-рамку и сопоставив буквы и цифры зашифрованного слова, затем нужно будет получившееся слово вписать в кодовую таблицу вместо цифр, а оставшиеся буквы вписать по-порядку. Получится вот такая кодовая таблица:
Атбаш
Изначально шифр использовался для еврейского алфавита, отсюда и название. Слово атбаш (אתבש) составлено из букв «алеф», «тав», «бет» и «шин», то есть первой, последней, второй и предпоследней букв еврейского алфавита. Этим задаётся правило замены: алфавит выписывается по порядку, под ним он же выписывается задом наперёд. Тем самым первая буква кодируется в последнюю, вторая - в предпоследнюю и т.д.
Фраза «ВОЗЬМИ ЕГО В ЭКСЕПШН» превращается при помощи этого шифра в «ЭРЧГТЦ ЪЬР Э ВФНЪПЖС». Онлайн-калькулятор шифра Атбаш
ROT1
Этот шифр известен многим детям. Ключ прост: каждая буква заменяется на следующую за ней в алфавите. Так, A заменяется на Б, Б на В и т.д., а Я заменяется на А. «ROT1» значит «ROTate 1 letter forward through the alphabet» (англ. «поверните/сдвиньте алфавит на одну букву вперед»). Сообщение «Хрюклокотам хрюклокотамит по ночам» станет «Цсялмплпубн цсялмплпубнйу рп опшбн». ROT1 весело использовать, потому что его легко понять даже ребёнку, и легко применять для шифрования. Но его так же легко и расшифровать.
Шифр Цезаря
Шифр Цезаря - один из древнейших шифров. При шифровании каждая буква заменяется другой, отстоящей от неё в алфавите не на одну, а на большее число позиций. Шифр назван в честь римского императора Гая Юлия Цезаря, использовавшего его для секретной переписки. Он использовал сдвиг на три буквы (ROT3). Шифрование для русского алфавита многие предлагают делать с использованием такого сдвига:

Я всё же считаю, что в русском языке 33 буквы, поэтому предлагаю вот такую кодовую таблицу:
Интересно, что в этом варианте в алфавите замены читается фраза «где ёж?»:)
Но сдвиг ведь можно делать на произвольное число букв - от 1 до 33. Поэтому для удобства можно сделать диск, состоящий из двух колец, вращающихся относительно друг друга на одной оси, и написать на кольцах в секторах буквы алфавита. Тогда можно будет иметь под рукой ключ для кода Цезаря с любым смещением. А можно совместить на таком диске шифр Цезаря с атбашем, и получится что-то вроде этого:

Собственно, поэтому такие шифры и называются ROT - от английского слова «rotate» - «вращать».
ROT5
В этом варианте кодируются только цифры, остальной текст остаётся без изменений. Производится 5 замен, поэтому и ROT5: 0↔5, 1↔6, 2↔7, 3↔8, 4↔9.
ROT13
ROT13 - это вариация шифра Цезаря для латинского алфавита со сдвигом на 13 символов. Его часто применяют в интернете в англоязычных форумах как средство для сокрытия спойлеров, основных мыслей, решений загадок и оскорбительных материалов от случайного взгляда.

Латинский алфавит из 26 букв делится на две части. Вторая половина записывается под первой. При кодировании буквы из верхней половины заменяются на буквы из нижней половины и наоборот.
ROT18
Всё просто. ROT18 - это комбинация ROT5 и ROT13:)
ROT47
Существует более полный вариант этого шифра - ROT47. Вместо использования алфавитной последовательности A–Z, ROT47 использует больший набор символов, почти все отображаемые символы из первой половины ASCII -таблицы. При помощи этого шифра можно легко кодировать url, e-mail, и будет непонятно, что это именно url и e-mail:)
Например, ссылка на этот текст зашифруется вот так: 9EEAi^^?@K5C]CF^82>6D^BF6DE^4CJAE^4:A96C^K2>6?2nURC@Ecf. Только опытный разгадывальщик по повторяющимся в начале текста двойкам символов сможет додуматься, что 9EEAi^^ может означать HTTP:⁄⁄ .
Квадрат Полибия
Полибий - греческий историк, полководец и государственный деятель, живший в III веке до н.э. Он предложил оригинальный код простой замены, который стал известен как «квадрат Полибия» (англ. Polybius square) или шахматная доска Полибия. Данный вид кодирования изначально применялся для греческого алфавита, но затем был распространен на другие языки. Буквы алфавита вписываются в квадрат или подходящий прямоугольник. Если букв для квадрата больше, то их можно объединять в одной ячейке.

Такую таблицу можно использовать как в шифре Цезаря. Для шифрования на квадрате находим букву текста и вставляем в шифровку нижнюю от неё в том же столбце. Если буква в нижней строке, то берём верхнюю из того же столбца. Для кириллицы можно использовать таблицу РОТ11 (аналог шифра Цезаря со сдвигом на 11 символов):

Буквы первой строки кодируются в буквы второй, второй - в третью, а третьей - в первую.
Но лучше, конечно, использовать «фишку» квадрата Полибия - координаты букв:
Под каждой буквой кодируемого текста записываем в столбик две координаты (верхнюю и боковую). Получится две строки. Затем выписываем эти две строки в одну строку, разбиваем её на пары цифр и используя эти пары как координаты, вновь кодируем по квадрату Полибия.
Можно усложнить. Исходные координаты выписываем в строку без разбиений на пары, сдвигаем на нечётное количество шагов, разбиваем полученное на пары и вновь кодируем.
Квадрат Полибия можно создавать и с использованием кодового слова. Сначала в таблицу вписывается кодовое слово, затем остальные буквы. Кодовое слово при этом не должно содержать повторяющихся букв.
Вариант шифра Полибия используют в тюрьмах, выстукивая координаты букв - сначала номер строки, потом номер буквы в строке.
Стихотворный шифр
Этот метод шифрования похож на шифр Полибия, только в качестве ключа используется не алфавит, а стихотворение, которое вписывается построчно в квадрат заданного размера (например, 10×10). Если строка не входит, то её «хвост» обрезается. Далее полученный квадрат используется для кодирования текста побуквенно двумя координатами, как в квадрате Полибия. Например, берём хороший стих «Бородино» Лермонтова и заполняем таблицу. Замечаем, что букв Ё, Й, Х, Ш, Щ, Ъ, Э в таблице нет, а значит и зашифровать их мы не сможем. Буквы, конечно, редкие и могут не понадобиться. Но если они всё же будут нужны, придётся выбирать другой стих, в котором есть все буквы.

РУС/LAT
Наверное, самый часто встречающийся шифр:) Если пытаться писать по-русски, забыв переключиться на русскую раскладку, то получится что-то типа этого: Tckb gsnfnmcz gbcfnm gj-heccrb? pf,sd gthtrk.xbnmcz yf heccre. hfcrkflre? nj gjkexbncz xnj-nj nbgf "njuj^ Ну чем не шифр? Самый что ни на есть шифр замены. В качестве кодовой таблицы выступает клавиатура.

Таблица перекодировки выглядит вот так:

Литорея
Литорея (от лат. littera - буква) - тайнописание, род шифрованного письма, употреблявшегося в древнерусской рукописной литературе. Известна литорея двух родов: простая и мудрая. Простая, иначе называемая тарабарской грамотой, заключается в следующем. Если «е» и «ё» считать за одну букву, то в русском алфавите остаётся тридцать две буквы, которые можно записать в два ряда - по шестнадцать букв в каждом:
Получится русский аналог шифра ROT13 - РОТ16 :) При шифровке верхнюю букву меняют на нижнюю, а нижнюю - на верхнюю. Ещё более простой вариант литореи - оставляют только двадцать согласных букв:

Получается шифр РОТ10 . При шифровании меняют только согласные, а гласные и остальные, не попавшие в таблицу, оставляют как есть. Получается что-то типа «словарь → лсошамь» и т.п.
Мудрая литорея предполагает более сложные правила подстановки. В разных дошедших до нас вариантах используются подстановки целых групп букв, а также числовые комбинации: каждой согласной букве ставится в соответствие число, а потом совершаются арифметические действия над получившейся последовательностью чисел.
Шифрование биграммами
Шифр Плейфера
Шифр Плейфера - ручная симметричная техника шифрования, в которой впервые использована замена биграмм. Изобретена в 1854 году Чарльзом Уитстоном. Шифр предусматривает шифрование пар символов (биграмм), вместо одиночных символов, как в шифре подстановки и в более сложных системах шифрования Виженера. Таким образом, шифр Плейфера более устойчив к взлому по сравнению с шифром простой замены, так как затрудняется частотный анализ.
Шифр Плейфера использует таблицу 5х5 (для латинского алфавита, для русского алфавита необходимо увеличить размер таблицы до 6х6), содержащую ключевое слово или фразу. Для создания таблицы и использования шифра достаточно запомнить ключевое слово и четыре простых правила. Чтобы составить ключевую таблицу, в первую очередь нужно заполнить пустые ячейки таблицы буквами ключевого слова (не записывая повторяющиеся символы), потом заполнить оставшиеся ячейки таблицы символами алфавита, не встречающимися в ключевом слове, по порядку (в английских текстах обычно опускается символ «Q», чтобы уменьшить алфавит, в других версиях «I» и «J» объединяются в одну ячейку). Ключевое слово и последующие буквы алфавита можно вносить в таблицу построчно слева-направо, бустрофедоном или по спирали из левого верхнего угла к центру. Ключевое слово, дополненное алфавитом, составляет матрицу 5х5 и является ключом шифра.
Для того, чтобы зашифровать сообщение, необходимо разбить его на биграммы (группы из двух символов), например «Hello World» становится «HE LL OW OR LD», и отыскать эти биграммы в таблице. Два символа биграммы соответствуют углам прямоугольника в ключевой таблице. Определяем положения углов этого прямоугольника относительно друг друга. Затем руководствуясь следующими 4 правилами зашифровываем пары символов исходного текста:
1) Если два символа биграммы совпадают, добавляем после первого символа «Х», зашифровываем новую пару символов и продолжаем. В некоторых вариантах шифра Плейфера вместо «Х» используется «Q».
2) Если символы биграммы исходного текста встречаются в одной строке, то эти символы замещаются на символы, расположенные в ближайших столбцах справа от соответствующих символов. Если символ является последним в строке, то он заменяется на первый символ этой же строки.
3) Если символы биграммы исходного текста встречаются в одном столбце, то они преобразуются в символы того же столбца, находящимися непосредственно под ними. Если символ является нижним в столбце, то он заменяется на первый символ этого же столбца.
4) Если символы биграммы исходного текста находятся в разных столбцах и разных строках, то они заменяются на символы, находящиеся в тех же строках, но соответствующие другим углам прямоугольника.
Для расшифровки необходимо использовать инверсию этих четырёх правил, откидывая символы «Х» (или «Q») , если они не несут смысла в исходном сообщении.
Рассмотрим пример составления шифра. Используем ключ «Playfair example», тогда матрица примет вид:

Зашифруем сообщение «Hide the gold in the tree stump». Разбиваем его на пары, не забывая про правило . Получаем: «HI DE TH EG OL DI NT HE TR EX ES TU MP». Далее применяем правила -:
1. Биграмма HI формирует прямоугольник, заменяем её на BM.
2. Биграмма DE расположена в одном столбце, заменяем её на ND.
3. Биграмма TH формирует прямоугольник, заменяем её на ZB.
4. Биграмма EG формирует прямоугольник, заменяем её на XD.
5. Биграмма OL формирует прямоугольник, заменяем её на KY.
6. Биграмма DI формирует прямоугольник, заменяем её на BE.
7. Биграмма NT формирует прямоугольник, заменяем её на JV.
8. Биграмма HE формирует прямоугольник, заменяем её на DM.
9. Биграмма TR формирует прямоугольник, заменяем её на UI.
10. Биграмма EX находится в одной строке, заменяем её на XM.
11. Биграмма ES формирует прямоугольник, заменяем её на MN.
12. Биграмма TU находится в одной строке, заменяем её на UV.
13. Биграмма MP формирует прямоугольник, заменяем её на IF.
Получаем зашифрованный текст «BM ND ZB XD KY BE JV DM UI XM MN UV IF». Таким образом сообщение «Hide the gold in the tree stump» преобразуется в «BMNDZBXDKYBEJVDMUIXMMNUVIF».
Двойной квадрат Уитстона
Чарльз Уитстон разработал не только шифр Плейфера, но и другой метод шифрования биграммами, который называют «двойным квадратом». Шифр использует сразу две таблицы, размещенные по одной горизонтали, а шифрование идет биграммами, как в шифре Плейфера.
Имеется две таблицы со случайно расположенными в них русскими алфавитами.

Перед шифрованием исходное сообщение разбивают на биграммы. Каждая биграмма шифруется отдельно. Первую букву биграммы находят в левой таблице, а вторую букву - в правой таблице. Затем мысленно строят прямоугольник так, чтобы буквы биграммы лежали в его противоположных вершинах. Другие две вершины этого прямоугольника дают буквы биграммы шифртекста. Предположим, что шифруется биграмма исходного текста ИЛ. Буква И находится в столбце 1 и строке 2 левой таблицы. Буква Л находится в столбце 5 и строке 4 правой таблицы. Это означает, что прямоугольник образован строками 2 и 4, а также столбцами 1 левой таблицы и 5 правой таблицы. Следовательно, в биграмму шифртекста входят буква О, расположенная в столбце 5 и строке 2 правой таблицы, и буква В, расположенная в столбце 1 и строке 4 левой таблицы, т.е. получаем биграмму шифртекста ОВ.
Если обе буквы биграммы сообщения лежат в одной строке, то и буквы шифртекста берут из этой же строки. Первую букву биграммы шифртекста берут из левой таблицы в столбце, соответствующем второй букве биграммы сообщения. Вторая же буква биграммы шифртекста берется из правой таблицы в столбце, соответствующем первой букве биграммы сообщения. Поэтому биграмма сообщения ТО превращается в биграмму шифртекста ЖБ. Аналогичным образом шифруются все биграммы сообщения:
Сообщение ПР ИЛ ЕТ АЮ _Ш ЕС ТО ГО
Шифртекст ПЕ ОВ ЩН ФМ ЕШ РФ БЖ ДЦ
Шифрование методом «двойного квадрата» дает весьма устойчивый к вскрытию и простой в применении шифр. Взламывание шифртекста «двойного квадрата» требует больших усилий, при этом длина сообщения должна быть не менее тридцати строк, а без компьютера вообще не реально.
Полиалфавитные шифры
Шифр Виженера
Естественным развитием шифра Цезаря стал шифр Виженера. В отличие от моноалфавитных это уже полиалфавитный шифр. Шифр Виженера состоит из последовательности нескольких шифров Цезаря с различными значениями сдвига. Для зашифровывания может использоваться таблица алфавитов, называемая «tabula recta» или «квадрат (таблица) Виженера». На каждом этапе шифрования используются различные алфавиты, выбираемые в зависимости от буквы ключевого слова.
Для латиницы таблица Виженера может выглядеть вот так:

Для русского алфавита вот так:

Легко заметить, что строки этой таблицы - это ROT-шифры с последовательно увеличивающимся сдвигом.
Шифруют так: под строкой с исходным текстом во вторую строку циклически записывают ключевое слово до тех пор, пока не заполнится вся строка. У каждой буквы исходного текста снизу имеем свою букву ключа. Далее в таблице находим кодируемую букву текста в верхней строке, а букву кодового слова слева. На пересечении столбца с исходной буквой и строки с кодовой буквой будет находиться искомая шифрованная буква текста.
Важным эффектом, достигаемым при использовании полиалфавитного шифра типа шифра Виженера, является маскировка частот появления тех или иных букв в тексте, чего лишены шифры простой замены. Поэтому к такому шифру применить частотный анализ уже не получится.
Для шифрования шифром Виженера можно воспользоваться Онлайн-калькулятором шифра Виженера . Для различных вариантов шифра Виженера со сдвигом вправо или влево, а также с заменой букв на числа можно использовать приведённые ниже таблицы:


Шифр Гронсвельда
Книжный шифр
Если же в качестве ключа использовать целую книгу (например, словарь), то можно зашифровывать не отдельные буквы, а целые слова и даже фразы. Тогда координатами слова будут номер страницы, номер строки и номер слова в строке. На каждое слово получится три числа. Можно также использовать внутреннюю нотацию книги - главы, абзацы и т.п. Например, в качестве кодовой книги удобно использовать Библию, ведь там есть четкое разделение на главы, и каждый стих имеет свою маркировку, что позволяет легко найти нужную строку текста. Правда, в Библии нет современных слов типа «компьютер» и «интернет», поэтому для современных фраз лучше, конечно, использовать энциклопедический или толковый словарь.
Это были шифры замены, в которых буквы заменяются на другие. А ещё бывают , в которых буквы не заменяются, а перемешиваются между собой.